Deriving Linear Attention and DeltaNet (Part 1)
Linear Attention Part 1 — From softmax to linear attention, delta rule, and gating
TL;DR
Softmax attention and sub-quadratic models like linear attention belong to the same class of models that make choices across four axes: how to store associative memory (memory architecture), which objective we try to optimize (objective), how to optimize (optimizer), and how to forget (retention). In this setting, we show that softmax attention is a degenerate case where we append everything to memory without any compression, optimization, or forgetting — for which we pay an unbounded KV cache and quadratic attention compute. Sub-quadratic models approximate this perfect recall by having a fixed-size memory and a tiny model that is trained online inside the forward-pass, with specific choices on the memory architecture, objective, optimizer and retention. We derive the finite-state recurrence by replacing the softmax similarity in attention with a finite-dim kernel, which allows us to factor out a fixed-size state matrix. By generalizing this further into we show how specific choices for and influence the four axes and where popular models are placed across them.
1. Setup
Transformers are currently THE default architecture for any foundational model as they can attend to the entire context and thus have perfect recall, and they can be trained very efficiently. But that recall is paid for with an unbounded KV cache (that grows linearly with context) and quadratic compute. Today’s workloads already strain our compute resources and will keep doing that because, as those models get better, we start giving them longer tasks on more context. Tomorrow’s 10–100M context sizes aren’t reachable with this, even with optimizations like Flash Attention, MQA/GQA, or KV compression; they buy us some time but they don’t bend the quadratic curve. So, planning ahead, we should ask: can we get excellent recall from a fixed-size state that is as good (or even better) as softmax attention, but with linear compute? And, will we even need softmax attention in the future?

2. Linear attention
Starting with the familiar equations for softmax attention.
where , and are the usual query, key and value matrices, with being the causal mask matrix to ensure tokens cannot attend into the future. Assume that the scaling is already folded into for clarity.
Replace with a general function that measures the similarity between and :
The plain dot product is one widely used choice.
We call a kernel if there is a such that . Having a kernel as our similarity function allows us to factor the query-dependent term out of the sum:
The same factoring applied to the denominator gives
Modern variants drop the denominator because it can introduce numerical instabilities and we already use normalisation like RMSNorm on the block/layer output anyway; additionally, we get some guarantees later on with gating that bounds . Footnote: (Katharopoulos et al., 2020) Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention Katharopoulos, Vyas, Pappas, Fleuret · ICML 2020 arXiv:2006.16236 keeps .
Dropping the denominator and incrementing inside the sum gives the linear-attention recurrence:
Each step writes a rank-1 matrix (the outer product of and ) into a fixed-size state of dimension . Total cost per token: regardless of sequence length.
Why softmax can’t fit this form. We mentioned that we want a similarity function that is a kernel with . The good thing is that softmax is also a kernel, the only problem is that its feature map is infinite-dimensional, so would be an infinite matrix we cannot materialize. To get a finite-state recurrence we have to pick a kernel with finite-dim . (Katharopoulos et al., 2020) Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention Katharopoulos, Vyas, Pappas, Fleuret · ICML 2020 arXiv:2006.16236 chose . That’s the original “linear attention”.
Most follow-up papers skip the feature map and take directly, without an explicit softmax-style weighted sum anymore. Generalizing it further, we can write
where (by convention) stands for whatever key-side vector the model writes — for linear attention, or directly. governs what we keep from the previous state and is the value being written at step . For linear attention it’s and .
3. Associative memory
But what is our goal again? With softmax or linear attention we want to retrieve the value for some pair that we have seen already, what we usually refer to as part of our context.
The linear-attention read-out with a query key is:
We can split the sum into our signal which we want to retrieve and some cross-talk/noise (here we assume matches some stored key exactly, with ):
The cross-talk term is what determines whether the recurrence can faithfully store many key–value pairs. If it gets bigger than the signal we won’t be able to retrieve .
In practice we want to approximate retrieval, such that similar queries should retrieve similar values:
The easy way to achieve this goal is to keep every pair around like softmax does:
As we keep all past key and value vectors of dimension and respectively, the KV cache size grows linearly with :
Linear attention compresses that into a fixed-size , where the compression has a capacity ceiling at stored key-value pairs:
Why linear attention has capacity
This shows up cleanly in two limit cases.
Orthogonal-key case (hard cap). If the stored keys are mutually orthogonal — for and — then the cross-talk vanishes and the read-out is exact:
But holds at most mutually orthogonal vectors. So in this regime the recurrence stores at most key-value pairs perfectly. That’s the hard cap.
Random-key case (soft cap, JL concentration). In practice the keys aren’t exactly orthogonal but rather whatever the model produces, and on average behave like random vectors. Take with i.i.d. entries . Each pairwise dot product has zero mean and variance (follows from Johnson–Lindenstrauss concentration):
The cross-talk term is a sum of approximately-independent contributions, so its variance adds:
(taking unit-norm values for clarity). The signal-to-noise ratio of the read-out is then
so exactly when . That’s the regime where retrieval starts breaking down.
The conclusion in both cases: linear attention can store roughly key-value pairs before cross-talk overwhelms the signal.
Putting that together we can look at the compression ratio between softmax attention and linear attention:
The interesting regime is , when the context is considerably larger than the dimension of our keys/values, and where every sub-quadratic recurrence model is forced to throw information away. The rest of the post is how to do that intelligently by increasing the effective capacity of and managing what gets forgotten. Different choices of (how the past decays) and (what the new write is) give different architectures.
4. Delta rule
Why we need a smarter write. Recall that linear attention writes
even when the past state already returns the right value at (i.e. ). Writing the same twice doubles the stored value at , amplifying cross-talk for every other key without adding any new information.
So what if we correct rather than just accumulate? The simplest objective for "" would be to just do one step of gradient descent on the L2 loss:
For it we can compute the gradient w.r.t. in closed-form:
This is just the outer product of the residual (how wrong the current read-out at is) and the key . Shape-wise it matches , so we can take one gradient step from with a step size :
Regrouping the terms gives us the delta rule:
So comparing it with our general formula, DeltaNet (Yang et al., 2024) Parallelizing Linear Transformers with the Delta Rule over Sequence Length Yang, Wang, Zhang, Shen, Kim · NeurIPS 2024 arXiv:2406.06484 is the choice and .
What does actually do? Assuming (in practice enforced by some normalization on the keys), is the projector onto the line spanned by , so shrinks any component along by a factor of and leaves anything orthogonal to untouched.
To make this concrete, let’s look at the read-out at the just-written key. Writing for whatever was stored at before the write, we get
i.e. a convex blend of the old and new value. With the write fully overwrites whatever was there; with we ignore the new write. And the read-out at any orthogonal key (with ) is just
completely unchanged. So writing at does not affect the read-out of exactly orthogonal keys.
In practice is per-token learnable, something like . The model can learn to assign small to input patterns that tend to be redundant (like filler-words) and large to patterns that tend to carry new information (like nouns).
Capacity is unchanged; what’s still missing. We get perfect read-out only when the stored key is exactly orthogonal to . The read-out at after the write of a new is
When is crowded — we’ve already stored many key–value pairs — a new key won’t be orthogonal to all of them. For any stored with noticeably non-zero, the equation above says the read-out at gets partially overwritten too: the second term scales down a -piece of what was stored along , and the third term adds a -piece of the new . So we end up with the same capacity ceiling as linear attention: DeltaNet still saturates around .
What DeltaNet does fix is the what we write: blind addition becomes an error-correcting write whose size is proportional to how wrong the current read-out at is. Concretely, writing the same twice is now a near no-op (the residual is already small on the second write), where linear attention would just double the value at and amplify the cross-talk.
What it does not fix is the what we forget. The partial-projects only along , so anything orthogonal to in is preserved exactly. A stale write from many steps ago in some direction stays in at full magnitude forever, unless we happen to write near again. DeltaNet never forgets, so let’s change that with gating.
Figure 1. Updated for DeltaNet:
| Model | |||
|---|---|---|---|
| Softmax | — (no finite ) | — | (infinite-dim) |
| Linear attention | |||
| DeltaNet | identity |
Modern sub-quadratic sequence models fit the form . governs what is kept or forgotten (acts on the key side, ) and is the new value written into memory.
5. Gating: learning to forget
DeltaNet fixes duplicate writes, but every orthogonal direction in persists forever — pure DeltaNet cannot forget. keeps accumulating stale writes and capacity never frees. The minimal fix is to add an exponential decay in front of the state.
Mamba2
If we take linear attention and add exponential decay we get Mamba2 (Dao & Gu, 2024) Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality Dao, Gu · ICML 2024 arXiv:2405.21060 : , , with per-token learnable.
Unrolled, a previous write at step contributes weight at the current step . This decays exponentially. But we still accumulate over already seen pairs: seeing the same twice still doubles the value and amplifies cross-talk while gaining no information.
Gated DeltaNet
If we apply the gating idea to DeltaNet we get Gated DeltaNet (Yang, Kautz, Hatamizadeh, 2024) Gated Delta Networks: Improving Mamba2 with Delta Rule Yang, Kautz, Hatamizadeh · 2024 arXiv:2412.06464 :
The two gates do orthogonal jobs: filters what gets written into , and controls how long what is stored stays around. Both are per-token learnable from alone, so they inherit the same content-vs-state caveat as Section 4’s — the gates see the input but not the current residual at . The cross-talk equation from Section 4 picks up an in front of the terms, but the structure is unchanged:
We still have the same capacity limits as the original DeltaNet (); gating doesn’t raise the ceiling, but it lets us recycle the slots that we have. In the best case we use the budget for useful KV pairs at a time.
6. Benchmark: S-NIAH
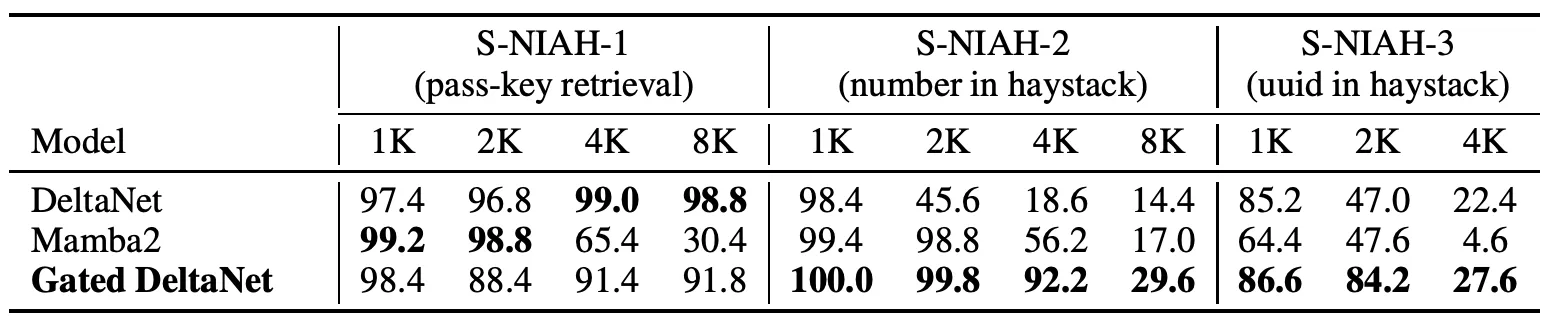
S-NIAH is RULER’s needle-in-haystack suite (Hsieh et al., 2024) RULER: What's the Real Context Size of Your Long-Context Language Models? Hsieh, Sun, Kriman, Acharya, Rekesh, Jia, Zhang, Ginsburg · 2024 arXiv:2404.06654 , with three subtasks: passkey retrieval (S-NIAH-1), number in haystack (S-NIAH-2), and uuid in haystack (S-NIAH-3).
DeltaNet is the right tool for the synthetic passkey (S-NIAH-1) — targeted updates are exactly what precise needle-recall needs, and it stays near-perfect through 8K. But it has no way to clear , so the real-world S-NIAH-2 and -3 trigger the §3 cross-talk story: stored values superimpose as the haystack grows, and accuracy collapses (98.4 → 14.4 from 1K → 8K on S-NIAH-2).
Mamba2 has the opposite problem. Its uniform gate can clear, but it can’t write precisely — so even on the synthetic passkey the needle gets co-decayed with the haystack as context grows (99.2 → 30.4 from 1K → 8K).
Gated DeltaNet pays a small price on synthetic recall (the gate discards information; 8K passkey sits around 90 instead of 99) and wins every cell on S-NIAH-2/3 — precise writes plus the ability to clear.
Both gates depend only on and not on or the current residual . They see the input, but not the actual mistake the state is making at . A state-aware step size that conditions on the residual would be the natural next step.
Figure 1. Updated:
| Model | |||
|---|---|---|---|
| Softmax | — (no finite ) | — | (infinite-dim) |
| Linear attention | |||
| Mamba2 | identity | ||
| DeltaNet | identity | ||
| Gated DeltaNet | identity |
Mamba2 contributes the scalar decay ; Gated DeltaNet stacks it on the DeltaNet gradient step.
Outlook
So far, every architecture has fit the same recurrence where only varies. We’ve seen two knobs: how we write ( — the delta rule) and how we forget (decay via — Mamba2 / Gated DeltaNet).
Look back at the move that gave us DeltaNet: one gradient step on . So can be viewed as not just a state being updated by a hand-tuned rule, but as a small model being trained as we read. DeltaNet is the special case in which that model has a single linear layer.
Part 2 commits to that view: stop calling a state, treat it as a tiny model updated online to remember the context. That framing is what opens up TTT, Titans, and the four axes introduced by MIRAS.
References
- Katharopoulos, Vyas, Pappas, Fleuret (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. ICML 2020. arXiv:2006.16236
- Yang, Wang, Zhang, Shen, Kim (2024). Parallelizing Linear Transformers with the Delta Rule over Sequence Length. NeurIPS 2024. arXiv:2406.06484
- Dao, Gu (2024). Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. ICML 2024. arXiv:2405.21060
- Yang, Kautz, Hatamizadeh (2024). Gated Delta Networks: Improving Mamba2 with Delta Rule. arXiv:2412.06464
- Hsieh, Sun, Kriman, Acharya, Rekesh, Jia, Zhang, Ginsburg (2024). RULER: What's the Real Context Size of Your Long-Context Language Models?. arXiv:2404.06654