Building Docker Hub for Typst Templates
Your PDF Stack Might Be From 1995. Here's a 2025 Version.
This is a continuation of the story told at post.
TLDR: Build something like Docker Hub for Typst Templates called papermake-registry
Publishing a template:
http --form POST http://localhost:3000/api/templates/myinvoice/publish \ main_typ@invoice.typ \ 'files[logo.png]'@logo.png \ metadata@metadata.jsonRendering it:
http POST http://localhost:3000/api/render/myinvoice:latest \ data:=@data.jsonPrologue
In the past year, I’ve seen two companies struggling with generating documents in the form of PDFs. Both are old companies with legacy tech stacks that make every new grad software developer wince.
One of these companies in the finance industry was forced to change as their old system couldn’t keep up with growing demands. While the old system was on-premises on servers in their basement, the new system was to be deployed in the cloud on AWS Lambda to reap the benefits of “infinite scaling” (or so they were promised). The project was supposed to be finished and go live in a matter of weeks—or at least that’s what management thought.
The second company, working in the manufacturing industry of cryogenic gases, had a different kind of problem. They were optimizing the process around loading and analyzing cryogenic gases. This includes printing out weigh bills and dangerous goods certificates for trucks leaving the factory. The company was working with factories all around Europe, from Czech Republic to Switzerland, so the certificates had to be in the factory-specific language and English. Weigh bills and certificates are normally standard documents, but many factories required minor adjustments, and for some larger customers in the industry like Coca Cola—they need the CO₂ from somewhere for the bubbles in your drink—they too required special certificates.
And because the company’s system was already handling the automatic printing process of the weigh bills, it soon handled other documents as well.
How was this implemented? Horribly—in multiple senses.
They used CrystalReports to do the rendering of the PDFs. The decision came mainly because all of the process data was contained in a spider web of database tables, and they wanted a tool that could print PDFs based on data from a database.
Fair enough. But.
Without critiquing the overall choice of CrystalReports too much (works only on Microsoft, and there only barely. Installation is finicky, it randomly crashed when using, which is super annoying when it deletes like an hour of progress), the biggest problem was probably the developer experience altogether.
- Data fetching was opaque.
The company used stored procedures (or short procedures) everywhere—compiled pieces of SQL code that are opaque. If they break, you have no clue why, where, or how.
They also used them for fetching the data for the PDF. And I’m not joking, but some of them were multiple thousands of lines long.
- Debugging & Reproducibility was horrible
Picture this: Your biggest customer calls at 3 PM on Friday. “Our certificates aren’t printing. Trucks can’t leave. We’re losing millions by the hour. Fix it now.” What should be a 5-minute debugging session becomes a multi-hour nightmare. Here’s the CrystalReports debugging process: First, we need a full production database backup—multiple gigabytes downloaded through two VPNs. Then we discover the real kicker: once an order is marked “completed,” the same stored procedure that generated the original certificate won’t work anymore. So we have to create a fake order, filling in dozens of irrelevant fields just to make the procedure happy.
For people who haven’t worked with CrystalReports (bless your soul), the tool somehow bakes database connection details directly into the .rpt template files. This means every debugging session requires rebuilding half of the customer’s production environment on your local machine. What could have been fixed in minutes now takes hours. Your customer is furious. Your weekend is ruined. All because testing a PDF template requires the complexity of launching a space shuttle.
Finally, because the rendering system required a full-fledged database, when we went to new clients or new factories and they wanted to see the templates, we could not show them. This led to them complaining about the templates after we deployed the system.
Watching this chaos unfold week after week, I started sketching a different approach. What if PDF generation could work like every other modern development workflow? My core principles were simple but radical in this context:
Transparency over opacity: Plain text templates instead of binary blobs Simplicity over complexity: JSON data instead of database spiderwebs Testability over prayer: If something breaks, you can reproduce it locally with two files
I built this vision around Typst, a powerful new typesetter written in Rust with markdown-like syntax. Instead of wrestling with CrystalReports’ visual designer, developers could write templates that looked like code. Instead of stored procedures pulling from 100 database tables, you’d send a JSON object. The entire debugging workflow became: “Here’s the template file, here’s the data file, here’s what broke.” No database dumps, no VPNs, no fake orders. Just files you could version control, review, and test like any other code. I called the prototype Keystone, and I’m pretty sure it died when I left the company. But the idea stuck with me.
Papermake-AWS
Months later—I had already left the company—I heard from the first company in the financial industry that they were still struggling with their new PDF rendering service. They were growing fast, and so their old, COBOL-like PDF rendering service was not keeping up with the demands. The new service was supposed to be built upon AWS Lambda to have nice scalability. But I also heard that they were considering some old weird tech stack (again), which motivated me to re-implement the idea around Typst and adapt it for serverless.
I implemented that in a few days over Easter (papermake-aws) and wrote a blog post about it: “Generating 1 Million PDFs in 10 Minutes”. I also posted it on LinkedIn which got some attention (around 100k impressions), and I even got invited to speak about it at a conference for senior engineers.
But I am not done with the topic.
While Lambda is great for scale, some teams need or want on-premise solutions because of privacy reasons or they want to use the servers in their basement.
Additionally, the AWS Lambda deployment of papermake had some problems:
-
Obviously only deployable on AWS Lambda
-
No version control on templates.
If you work in a regulated industry, like finance, medicine, or manufacturing, you have to document everything. This includes the templates that you use to print (medical) certificates. That’s why there are often compliance teams that have to check the template versions, often by hand. Even if you are not working in a regulated industry, you probably want version control either way. If something breaks, it’s easier to figure out why because you know which version is used. And you avoid naming your files “invoice_final_revised_v2.docx”, which helps everyone’s sanity.
Additional flaws:
- Only simple templates
By simple templates I mean Typst templates that are one file and have no dependencies on files like other Typst files to import functions or assets like images. Not ideal.
- Testability & Reproducibility
At the other company we often had the case that a document render failed and we had absolutely no clue why. I want to see which exact template and what kind of data was used, such that I can fix it fast.
Plus, just throwing a Typst template into an S3 bucket and remembering its name is hardly convenient.
Writing Docker Hub for Templates
My idea was to design and build a registry on top of the core papermake rendering functionality.
The core ideas this builds upon are pretty simple:
Content-addressable storage. Every template gets hashed. Same content = same hash = stored once. This means if you have 100 invoice templates that all use the same company logo, that logo is stored exactly once but referenced 100 times. It’s nice for storage costs and also for reproducibility.
Mutable tags pointing to immutable content. Just like Docker. You can have invoice:latest that points to different versions over time, but invoice@sha256:abc123... always points to the exact same bytes. This gives you both convenience (“just give me the latest”) and reproducibility (“I need exactly the version from three months ago when everything was working”). Using the specific hash guarantees that the used template will be the same.
Templates as bundles. Unlike the AWS Lambda version where everything had to be crammed into one file, templates can now include multiple files—your main template, helper functions in separate Typst files, assets like logos and fonts. Everything gets packaged together and put into a virtual filesystem that Typst uses.
/// Publish a template bundle to the registry////// This method implements the "store files → create manifest → update refs" workflow////// Returns the manifest hash for content-addressable accesspub async fn publish( &self, bundle: TemplateBundle, namespace: &str, tag: &str,) -> Result<String, RegistryError> { // Step 1: Validate the bundle bundle.validate().map_err(|e| { RegistryError::Template(crate::error::TemplateError::invalid(e.to_string())) })?;
// Step 2: Store individual files as blobs let mut file_hashes = BTreeMap::new();
// Store main.typ let main_hash = ContentAddress::hash(bundle.main_typ()); let main_blob_key = ContentAddress::blob_key(&main_hash); self.storage .put(&main_blob_key, bundle.main_typ().to_vec()) .await .map_err(|e| RegistryError::Storage(StorageError::backend(e.to_string())))?;17 collapsed lines
file_hashes.insert("main.typ".to_string(), main_hash);
// Store additional files for (file_path, file_content) in bundle.files() { let file_hash = ContentAddress::hash(file_content); let file_blob_key = ContentAddress::blob_key(&file_hash); self.storage .put(&file_blob_key, file_content.clone()) .await .map_err(|e| RegistryError::Storage(StorageError::backend(e.to_string())))?; file_hashes.insert(file_path.clone(), file_hash); }
// Step 3: Create manifest let manifest = Manifest::new(file_hashes, bundle.metadata().clone()).map_err(|e| { RegistryError::ContentAddressing(crate::error::ContentAddressingError::manifest_error( e.to_string(), )) })?;
17 collapsed lines
// Step 4: Store manifest let manifest_bytes = manifest.to_bytes().map_err(|e| { RegistryError::ContentAddressing(crate::error::ContentAddressingError::manifest_error( e.to_string(), )) })?; let manifest_hash = ContentAddress::hash(&manifest_bytes); let manifest_key = ContentAddress::manifest_key(&manifest_hash); self.storage .put(&manifest_key, manifest_bytes) .await .map_err(|e| RegistryError::Storage(StorageError::backend(e.to_string())))?;
// Step 5: Update reference (tag) let ref_key = ContentAddress::ref_key(namespace, tag); self.storage .put(&ref_key, manifest_hash.as_bytes().to_vec()) .await .map_err(|e| RegistryError::Storage(StorageError::backend(e.to_string())))?;
// Return the manifest hash for content-addressable access Ok(manifest_hash)}Server-side rendering. POST /render/invoice:latest with your JSON data, get a PDF back. You don’t need to install anything fancy.
You know that CrystalReports hell I described? Where reproducing one failed render meant downloading gigabytes of database dumps through multiple VPNs, setting up fake orders, and sacrificing your sanity and time? I want the exact opposite of that experience.
Every single render gets logged. The exact template hash, input data hash, output PDF hash. When something inevitably breaks at the worst possible moment, you know exactly what happened.
This means when your biggest customer calls you screaming that the medical certificates are printing wrong and their truck drivers cannot leave the premises, you can pull up the exact render in under a minute. You see the exact template, the exact data, and you immediately know if the template is broken or if they sent you garbage input.
No more “let me just download your entire production database real quick.”
Debugging Failed Render (Under 1 Minute)
Customer calls: “Certificate printing failed for Order #12345!”
- Look up render by order/timestamp or data content:
GET /renders?search=12345&limit=10GET /renders?data_contains='#12345'&limit=10- Find failed render entry:
render_id: abc-123-def template_ref: "cert:v2.1" data_hash: "sha256:input_data_hash" error: "Missing field: expiry_date"- Reproduce failed render:
GET /renders/abc-123-def/data -o data.jsonPOST /renders/cert:v2.1 -d $data`# Error: Template expects 'expiry_date' but got 'expire_date'- Test locally:
vi data.json # update data and test againPOST /renders/cert:v2.1 -d $data-
Fix discovered:
Either fix template or data format No database dumps, no VPNs, no fake orders
Total time: 45 seconds
Actually Building This
The whole thing ended up being three components that build on top of each other:
papermake - The Typst rendering engine. Give it a template bundle (main file + whatever assets) and JSON data, it gives you PDF bytes. Uses a virtual filesystem so templates can #include other files naturally.
papermake-registry - Content-addressable storage with publishing and versioning. S3 for blobs (templates, input data, PDFs), ClickHouse for tracking every render and doing analytics. Everything gets SHA-256 hashed and put into the BlobStorage:
papermake-server - HTTP layer that ties everything together. Upload templates via multipart form, render with JSON POST, browse your render history.
Component Interaction Flow:──────────────────────────
POST /render/invoice:latest + JSON data│├─ papermake-server (HTTP layer)│ ├─ Parse reference: "invoice:latest"│ ├─ Validate JSON data│ └─ Generate render_id│├─ papermake-registry (Storage layer)│ ├─ Resolve tag: "invoice:latest" → manifest_hash│ ├─ Load manifest: manifest_hash → file_map│ ├─ Create RegistryFileSystem(file_map)│ └─ Store render metadata in ClickHouse│├─ papermake (Typst engine)│ ├─ Initialize TypstWorld with RegistryFileSystem│ ├─ Inject data via #sys.inputs.data│ ├─ Compile template → PDF bytes│ └─ Return PDF or CompileError│└─ Response: ├─ Success: PDF bytes + render_id └─ Failure: Error details + render_id for debuggingPOST /templates/{name}/publish?tag={tag} # Upload templateGET /templates # List all templatesGET /templates/{name}/tags # List template versionsPOST /render/{name}:{tag} # Render template to PDFGET /renders?limit=N # Recent render historyGET /renders/{id}/pdf # Download rendered PDFGET /analytics/volume?days=N # Render volume over timewebui
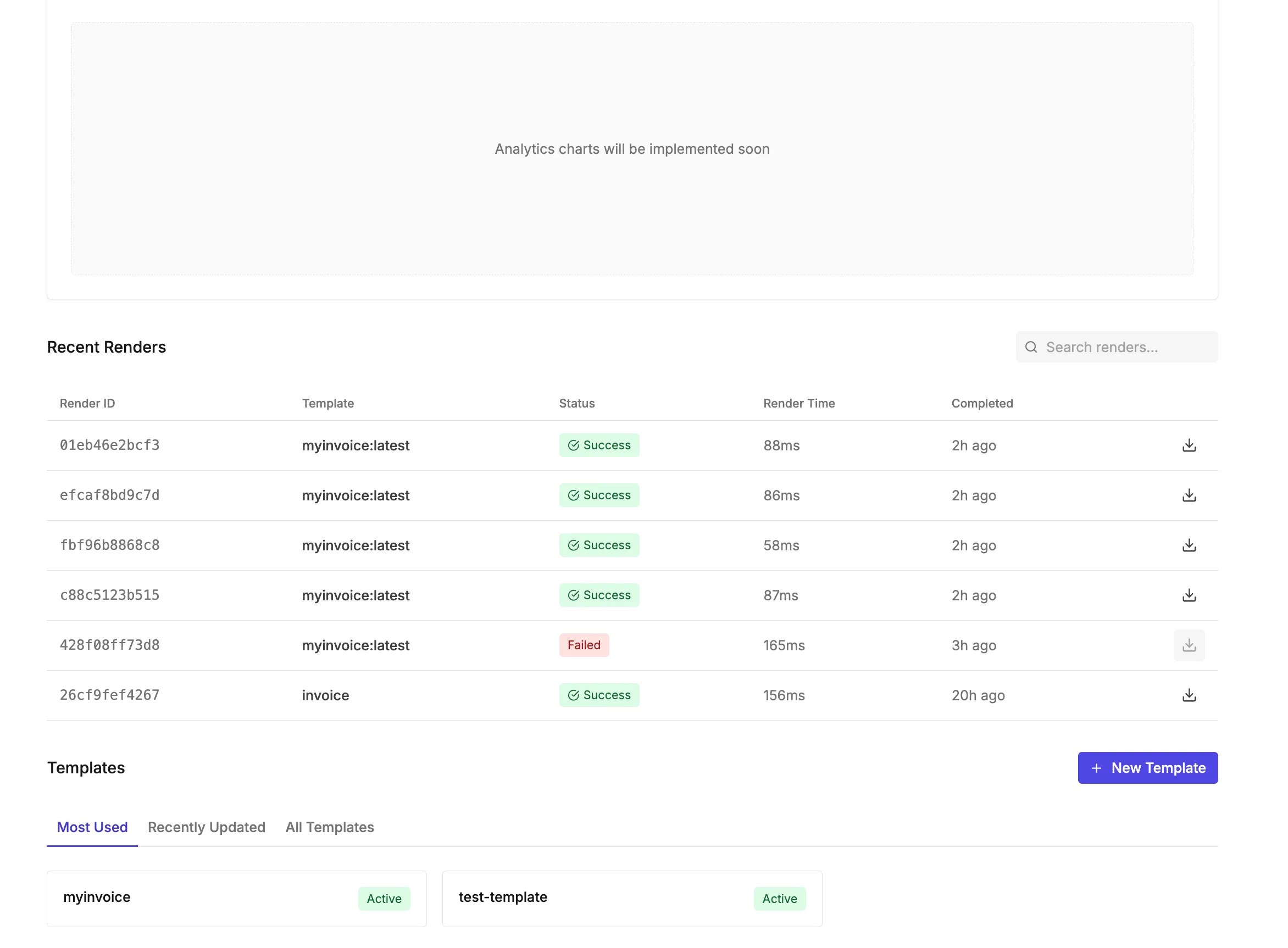
Still very early in development. Let’s see how much motivation I have to finish it.
This should be the main interface to edit and publish templates.
Who Should Care About This?
If you’re hemorrhaging money on slow PDF rendering: Companies like Stripe generate millions of PDFs daily. At ~10ms per render (100 PDFs/second per core), this could be the fastest rendering engine available. Faster rendering means fewer servers, which means more money in your pocket instead of AWS’s.
If compliance is killing your velocity: Finance, healthcare, and manufacturing companies often have dedicated teams manually reviewing template versions. Content-addressable storage means you can prove exactly which template version generated which document, three months after the fact. No more “invoice_final_revised_v3_ACTUALLY_FINAL.rpt” files.
If debugging production issues gives you nightmares: Any developer who’s had to reconstruct half of production just to reproduce a failed PDF render knows this pain. When your biggest customer calls screaming about broken certificates, you want to pull up the exact failure in 45 seconds, not 45 minutes.
It’s 2025. Document generation shouldn’t feel like archaeological excavation. The same engineering practices we use everywhere else—version control, content addressing, reproducible builds—should apply here too.
The question isn’t whether you need better PDF tooling. It’s whether you’re ready to stop accepting the status quo.
Code’s on GitHub if you want to give it a spin or mess with it.